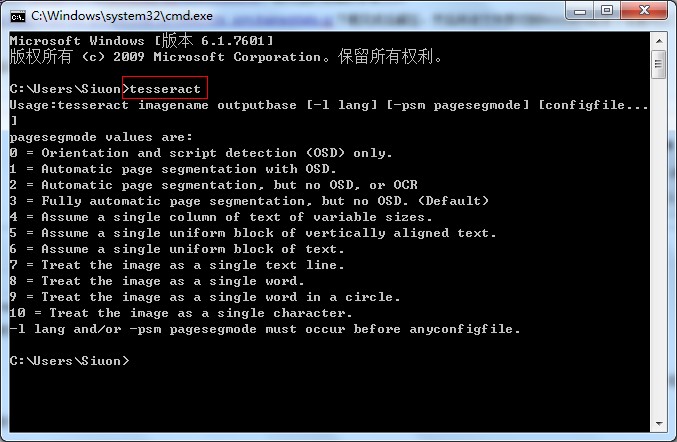
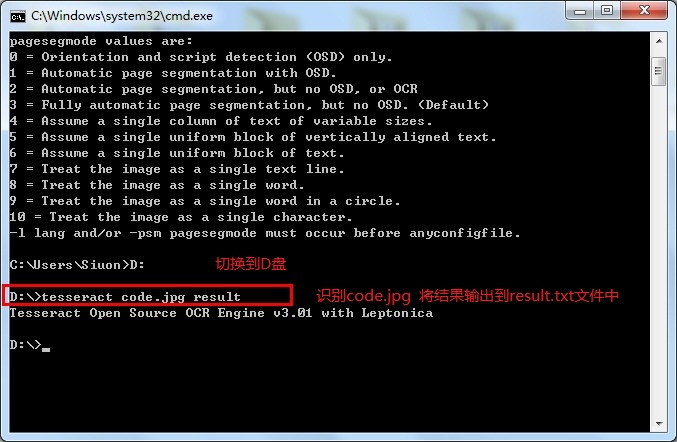
Tesseract OCR
5.3.3.20231005- 软件大小:47.8MB
- 更新时间:2024-03-07
- 星级指数:
- 软件平台:电脑版
- 软件语言:多语言
- 系统类型:支持32/64位
- 下载次数:87270
- 安全监测:[无病毒, 正式版, 无插件]
- 操作系统:winall/win7/win10/win11
本地纯净下载纯净官方版
软件介绍
 Tesseract OCR是一款OCR(optical character recognition,光学字符识别)开源库,可将包含文本的图像识别为计算机文字(计算机黑白点阵)。图像中的文本一般为印刷体文本。
Tesseract OCR是一款OCR(optical character recognition,光学字符识别)开源库,可将包含文本的图像识别为计算机文字(计算机黑白点阵)。图像中的文本一般为印刷体文本。
软件特色
软件安装
使用方法
软件问答
软件图集